Craic has released a new tool to help count features in images. This can be used in a range of applications such as counting buildings in satellite images, bacterial colonies and cell types in histology images.
It takes the form of a Ruby Sinatra application that fetches remote images and Javascript in the client web page that implements the marking and counting functions.
The user can choose the shape and color of the marker. The current total is updated as features are clicked and the coordinates of each point are stored internally.
The image with the user's marks can then be saved to a PNG format file and the list of coordinate pairs can be displayed in a separate window.
The graphics and interaction are implemented with Canvas and Javascript and make use of the wonderful Canvas2Image code from Jacob Seidelin which allows the current state of a canvas element to be saved to an image file.
The live application is hosted at Heroku and can be accessed at http://counter.craic.com
The code is distributed freely under the terms of the MIT license and is archived at Github
Wednesday, December 5, 2012
Tuesday, December 4, 2012
Counting Temporary Shelters in Satellite Images using OpenCV
A number of areas of data analysis are dominated by sophisticated algorithms, intensive computation and, in some cases, limited access to raw data. Examples include the analysis of satellite imagery, feature extraction from video, protein structure analysis and language processing.
I am interested in how simple, approximate methods can be used to extend the application of these technologies. While simple approaches will clearly not match the accuracy and resolution of complex methods, they can, by nature of their simplicity, be implemented and deployed more easily and hence more widely.
I have just posted the code for one of these projects to the Craic Github site. The application involves image processing of satellite images downloaded from Google Maps in order to estimate the number of temporary dwellings or shacks in the slums of Port-au-Prince in Haiti.
The satellite images of Port-au-Prince show large areas covered with small white, blue and rust colored squares. These are the slums of the city in areas such as St.Martin, Cite Soleil and others.
The blue features are very distinctive and most likely represent the ubiquitous blue plastic tarpaulins the you can find at any hardware store.
Using the Python interface to the wonderful OpenCV image processing library, I wrote a simple application that identifies blue features below a cutoff size and then computes their area. By fetching adjacent squares that tile across the city, and calculating the area of blue features, I can come up with an matrix showing the relative density of the slums.
The approach is undoubtedly simplistic (the code is only about 35 lines of Python) but it demonstrates how simple approaches can be successfully applied to complex and sophisticated types of data. You do not always need access to expensive commercial software and proprietary datasets in order to work in these fields.
The code is made freely available at https://github.com/craic/count_shelters and you can read my write up of the work so far, with example images HERE.
Thursday, November 1, 2012
Tutorial on JS/JQuery Bookmarklets
I recently needed to implement a JavaScript bookmarklet for a new project. There are many web resources available but even so I had a bit of a learning curve to contend with.
In the hope of lessening that burden on future users, I've written up a tutorial on two types of bookmarklets with simple, annotated examples and posted all the code on our Github page.
The simplest form of bookmarklet is a chunk of JS code contained in the Bookmarklet URL that invokes some action. This is a direct approach - you select some text, you click the bookmarklet and you get a result. If you want to repeat the process with some other text on the page then you have to click the bookmarklet link again.
However, for many applications you need to invoke an action multiple times on a single page - looking up words in a dictionary would be a good example. Having to click on a Bookmarklet link every time is not a good solution. Instead you want to modify the behaviour of the page by injecting a custom JS script. A bookmarklet can be used to initiate this. So you end up with three scripts, two of which are slightly modified, general purpose scripts.
The bulk of the code for this second approach comes from how-to-create-a-jquery-bookmarklet, written by Brett Barros of latentmotion.com, with some code input from Paul Irish.
To fully benefit from the tutorial, you should download the project, run 'bundle install' and 'rackup -p 4567' to set up a local Sinatra server, then point your browser to http://localhost:4567
In the hope of lessening that burden on future users, I've written up a tutorial on two types of bookmarklets with simple, annotated examples and posted all the code on our Github page.
The simplest form of bookmarklet is a chunk of JS code contained in the Bookmarklet URL that invokes some action. This is a direct approach - you select some text, you click the bookmarklet and you get a result. If you want to repeat the process with some other text on the page then you have to click the bookmarklet link again.
However, for many applications you need to invoke an action multiple times on a single page - looking up words in a dictionary would be a good example. Having to click on a Bookmarklet link every time is not a good solution. Instead you want to modify the behaviour of the page by injecting a custom JS script. A bookmarklet can be used to initiate this. So you end up with three scripts, two of which are slightly modified, general purpose scripts.
The bulk of the code for this second approach comes from how-to-create-a-jquery-bookmarklet, written by Brett Barros of latentmotion.com, with some code input from Paul Irish.
To fully benefit from the tutorial, you should download the project, run 'bundle install' and 'rackup -p 4567' to set up a local Sinatra server, then point your browser to http://localhost:4567
Monday, October 29, 2012
Rails 3.2 Asset Pipeline - 'require_tree' is evil !
I have been battling the Asset Pipeline in Rails 3 for a couple of days - and finally I've got it working
An important part of the Asset Pipeline is the use of Manifest files in app/assets/javascripts and stylesheets which determine the specific files to include and, in some cases, the order in which they are processed.
The default javascripts Manifest file has these lines:
That reads as:
- process jquery, then jquery_ujs
- process anything in this file (self)
- process all the files in this directory tree (require_tree)
I don't have many JS files in my app - three custom JS files written by myself and a couple of third party libraries.
I try and follow defaults as far as possible but require_tree has two BIG problems.
First is that it processes ALL the files in the directory tree.
Second is that the ORDER is UNDEFINED.
It is common for JS libraries to distribute their code along with examples and minimized versions of the code. In the past I would just drop these distributions in the javascripts directory and then specify which of the files should be included in my app.
So one problem with require_tree is that it will process both a 'native' and minimized version of the same library is both are present. That results in the same functions being defined multiple times - and that seems to be a real problem if a library includes it's own copy of jQuery.
Not specifying the order of processing is the other BIG issue. For libraries with a 'core' JS file along with others will typically require that the core library is processed first.
The solution is to avoid require_tree at all costs. Put only the JS files that you absolutely need in app/assets/javascripts and specify them EXPLICITLY in the order they should be processed.
In my example, my application.js file becomes:
I strongly recommend that you start out with everything clearly defined like this. Once you have it all working then you can remove unused files and simplify application.js - if not, you risk going through the same debugging misery that I just went through.
An important part of the Asset Pipeline is the use of Manifest files in app/assets/javascripts and stylesheets which determine the specific files to include and, in some cases, the order in which they are processed.
The default javascripts Manifest file has these lines:
//= require jquery //= require jquery_ujs //= require_self //= require_tree .
That reads as:
- process jquery, then jquery_ujs
- process anything in this file (self)
- process all the files in this directory tree (require_tree)
I don't have many JS files in my app - three custom JS files written by myself and a couple of third party libraries.
I try and follow defaults as far as possible but require_tree has two BIG problems.
First is that it processes ALL the files in the directory tree.
Second is that the ORDER is UNDEFINED.
It is common for JS libraries to distribute their code along with examples and minimized versions of the code. In the past I would just drop these distributions in the javascripts directory and then specify which of the files should be included in my app.
So one problem with require_tree is that it will process both a 'native' and minimized version of the same library is both are present. That results in the same functions being defined multiple times - and that seems to be a real problem if a library includes it's own copy of jQuery.
Not specifying the order of processing is the other BIG issue. For libraries with a 'core' JS file along with others will typically require that the core library is processed first.
The solution is to avoid require_tree at all costs. Put only the JS files that you absolutely need in app/assets/javascripts and specify them EXPLICITLY in the order they should be processed.
In my example, my application.js file becomes:
//= require jquery //= require jquery_ujs //= require ./tabs_timeline_simple //= require ./tandem_select //= require ./raphael-min //= require ./facebox
I strongly recommend that you start out with everything clearly defined like this. Once you have it all working then you can remove unused files and simplify application.js - if not, you risk going through the same debugging misery that I just went through.
Thursday, October 25, 2012
Upgrading from Rails 3.0 to 3.1 - Issues with Javascripts
I have been upgrading a Rails app from 3.0.10 to 3.1.5.
The BIG difference with 3.1 is the use of the Assets pipeline which requires that you move images, stylesheets and javascripts from public/* to app/assets/*. In the case of Stylesheets and Javascripts you also put these under the control of a Sprockets Manifest file: application.js or application.css.scss
That Manifest file caused me problems with my javascripts...
I followed the advice in the Railscasts Episode 282 (which I recommend you look at) and put these lines into my application.js
Jquery is supposed to 'just be there' if you have the jquery-rails gem installed.
I think there were a two, maybe three, issues.
1: Sprockets requires that there are NO BLANK LINES in the Manifest file BEFORE the end of the lines that should be processed. In Rails 3.2 the default file says that explicitly but if you are creating your own that is an easy thing to overlook.
2: Look at the 4 lines shown above. The first two are 'require', followed by a SPACE and then the name of the javascript file.
The Third is 'require_self' - underscore, no space - that means process any JS code in this file.
The Fourth is 'require_tree' - underscore, no space - and that means process ALL JS files in this directory.
If you type these lines in and happen to use a space instead of the underscore then Sprockets will look for JS file called 'self' and 'tree' - and won't find them. So be very careful tying those in.
3: The main problem was the require_tree line
I have a number of JS files that are included as needed in certain views. At the top of each view page I specify those with a content_for block like this:
That has worked just fine in the past and I kept all the custom JS files in the javascripts directory. But require_tree will load ALL of them on EVERY page. I assume that there are some variable/function names that are duplicated and/or conflicting and so with all that loaded, nothing worked.
The solution is to get rid of the require_tree line completely.
If I had JS files that should be included in each page then I would 'require' each of them explicitly. This is the same approach that Ryan Bates suggests for CSS files. It just gives you more flexibility.
The BIG difference with 3.1 is the use of the Assets pipeline which requires that you move images, stylesheets and javascripts from public/* to app/assets/*. In the case of Stylesheets and Javascripts you also put these under the control of a Sprockets Manifest file: application.js or application.css.scss
That Manifest file caused me problems with my javascripts...
I followed the advice in the Railscasts Episode 282 (which I recommend you look at) and put these lines into my application.js
//= require jquery //= require jquery_ujs //= require_self //= require_tree .But when I ran my app none of my javascript functions were working. Looking at the source for one of the pages I saw this link
<script src="/assets/application.js" type="text/javascript"></script>Clicking on brought up a message, instead of a JS file, saying that Sprockets was unable to find the file 'jquery'
Jquery is supposed to 'just be there' if you have the jquery-rails gem installed.
I think there were a two, maybe three, issues.
1: Sprockets requires that there are NO BLANK LINES in the Manifest file BEFORE the end of the lines that should be processed. In Rails 3.2 the default file says that explicitly but if you are creating your own that is an easy thing to overlook.
2: Look at the 4 lines shown above. The first two are 'require', followed by a SPACE and then the name of the javascript file.
The Third is 'require_self' - underscore, no space - that means process any JS code in this file.
The Fourth is 'require_tree' - underscore, no space - and that means process ALL JS files in this directory.
If you type these lines in and happen to use a space instead of the underscore then Sprockets will look for JS file called 'self' and 'tree' - and won't find them. So be very careful tying those in.
3: The main problem was the require_tree line
I have a number of JS files that are included as needed in certain views. At the top of each view page I specify those with a content_for block like this:
<% content_for :custom_javascript_includes do %> <%= javascript_include_tag "raphael.js" %> <%= javascript_include_tag "tabs_timeline_simple.js" %> <% end %>and in my application.html file I have
<%= javascript_include_tag "application" %> <%= yield :custom_javascript_includes %>
That has worked just fine in the past and I kept all the custom JS files in the javascripts directory. But require_tree will load ALL of them on EVERY page. I assume that there are some variable/function names that are duplicated and/or conflicting and so with all that loaded, nothing worked.
The solution is to get rid of the require_tree line completely.
If I had JS files that should be included in each page then I would 'require' each of them explicitly. This is the same approach that Ryan Bates suggests for CSS files. It just gives you more flexibility.
Wednesday, October 24, 2012
Uploading contents of a PostgreSQL database to Heroku without db:push
I just created a new Rails app on my local machine and want to deploy it to Heroku. I've done this before and the uploading of the code typically works great - and it did today.
Then I wanted to upload the contents of a small PostgreSQL database to Heroku - and that's where I ran into issues.
Heroku has recently switched from a Heroku gem to Heroku Toolbelt which I installed onto my Mac OS X machine.
I should be able to run 'heroku db:push' from my Rails app and the data would get moved over using the taps gem. But it failed with this error:
I dug around in /usr/local/heroku and hacked /usr/local/heroku/lib/heroku/command/db.rb to tell me what it thought the load path for ruby gems was, using this line:
And then I found mention of a page on Heroku's site that deals with the pgbackups addon. Part of that describes how to import from a PostgreSQL backup directly, without having to use the heroku clients or taps.
I followed that and it worked great - here are the steps involved. Your starting data must be in PostgreSQL and you need to have an account on Amazon S3 (and know how to use it)
1: On your machine create a backup of your PostgreSQL database - 'mydb' is your database name and 'myuser' is your database user.
3: Check that you can get the file back out of S3 using curl
Then I wanted to upload the contents of a small PostgreSQL database to Heroku - and that's where I ran into issues.
Heroku has recently switched from a Heroku gem to Heroku Toolbelt which I installed onto my Mac OS X machine.
I should be able to run 'heroku db:push' from my Rails app and the data would get moved over using the taps gem. But it failed with this error:
$ heroku db:push ! Taps Load Error: cannot load such file -- taps/operation ! You may need to install or update the taps gem to use db commands. ! On most systems this will be: ! ! sudo gem install tapsI have taps installed, so what is going on? Well, I'm not sure but I run my rubies under rbenv which allows you to manage multiple versions - and Heroku's client doesn't seem able to figure out where the gems are located with rbenv.
I dug around in /usr/local/heroku and hacked /usr/local/heroku/lib/heroku/command/db.rb to tell me what it thought the load path for ruby gems was, using this line:
STDERR.puts "DEBUG: load path #{$:}"
The paths given in that were all in /usr/local/heroku/vendor/gems and my gem paths were nowhere to be found. I tried installing the taps, sqlite3 and sequel gems to that directory and I was able to get a bit further but I still couldn't get all the way - so I gave up on that path.And then I found mention of a page on Heroku's site that deals with the pgbackups addon. Part of that describes how to import from a PostgreSQL backup directly, without having to use the heroku clients or taps.
I followed that and it worked great - here are the steps involved. Your starting data must be in PostgreSQL and you need to have an account on Amazon S3 (and know how to use it)
1: On your machine create a backup of your PostgreSQL database - 'mydb' is your database name and 'myuser' is your database user.
$ pg_dump -Fc --no-acl --no-owner -h localhost -U myuser mydatabase > mydb.dump2: Transfer that to an Amazon S3 bucket and either make it world readable or set a temporary access url.
3: Check that you can get the file back out of S3 using curl
$ curl 'https://s3.amazonaws.com/mybucket/mydb.dump' > tmp $ ls -l tmp4: Enable the pgbackups addon in Heroku
$ heroku addons:add pgbackups5: Get the name of the Heroku database that you will restore to, by capturing a backup from the empty heroku db:
$ heroku pgbackups:capture HEROKU_POSTGRESQL_CRIMSON_URL (DATABASE_URL) ----backup---> b001 Capturing... done Storing... done
6: Restore to that database from the S3 URL
$ heroku pgbackups:restore HEROKU_POSTGRESQL_CRIMSON_URL 'https://s3.amazonaws.com/mybucket/mydb.dump'
7: Test it out - my app was already up so I just had to browse to the appropriate page and there were all my records.
8: Remove your S3 file
DONE !
Thursday, September 27, 2012
Rails 3 - New Model is not recognized
I created a new Model in a Rails 3 application, along with a database table - but because I was not creating a controller or views I did not use a rails generator and just created the file by hand.
The contents followed exactly the format of other Model files and I was careful to use a Plural name for the database table and a Singular name for the model class.
But when I ran the application, either in the console or as a server, I kept getting an error reporting the Model name as an 'uninitialized constant'.
I double and triple checked everything but no luck getting it to work. Poking around the web I found mention of the Lazy Loading feature in Rails whereby classes are not loaded until they are needed.
Along with that was mention that using the command 'Rails.application.eager_load!' in the console might solve the problem. indeed it did - but only in the Rails console...
The problem turned out to be that the model FILE name was PLURAL. The Model class itself was singular - which is correct - but the lazy loading mechanism was using this (I assume) to define the filename in which to find the Model. Because my was plural it could not find the file and because it did not find a model it assumed that my Model name was a constant and then found that to be uninitialized.
It's a confusing error message and I wonder if there might be a way for Rails to figure out that I wanted a model. But I figure this is a side effect of the Rails machinery for inferring model, controller, etc. names.
Ah well... live and learn...
The contents followed exactly the format of other Model files and I was careful to use a Plural name for the database table and a Singular name for the model class.
But when I ran the application, either in the console or as a server, I kept getting an error reporting the Model name as an 'uninitialized constant'.
I double and triple checked everything but no luck getting it to work. Poking around the web I found mention of the Lazy Loading feature in Rails whereby classes are not loaded until they are needed.
Along with that was mention that using the command 'Rails.application.eager_load!' in the console might solve the problem. indeed it did - but only in the Rails console...
The problem turned out to be that the model FILE name was PLURAL. The Model class itself was singular - which is correct - but the lazy loading mechanism was using this (I assume) to define the filename in which to find the Model. Because my was plural it could not find the file and because it did not find a model it assumed that my Model name was a constant and then found that to be uninitialized.
It's a confusing error message and I wonder if there might be a way for Rails to figure out that I wanted a model. But I figure this is a side effect of the Rails machinery for inferring model, controller, etc. names.
Ah well... live and learn...
Thursday, September 20, 2012
Microsoft AutoUpdate doesn't...
I got this message when I started up MS Word on my Mac this morning:

In other words, Microsoft AutoUpdate does not auto update... :^{
Compare that to the Google Chrome web browser which auto updates itself without requiring any action from myself and without requiring a browser restart.

In other words, Microsoft AutoUpdate does not auto update... :^{
Compare that to the Google Chrome web browser which auto updates itself without requiring any action from myself and without requiring a browser restart.
Monday, August 27, 2012
Preventing Excel from wrongly interpreting Strings in CSV files as Exponential numbers
MS Excel and Apple Numbers both attempt to guess the format of the contents of each cell when they open up a CSV file. Most of the time this is fine but in some cases it causes a big problem.
If you have a string with numbers and the letter E then both programs will treat this as a number in exponential notation.
For example, the string 229E10 will be converted to 2.29E+12
What makes it worse is that you cannot change it back to the original text using the cell format options.
I run into this problem with strings that represent microtiter plate and well assignments. For example, 229E10 refers to plate 229 row E column 10.
I just want the spreadsheet program to take what I give it as text. Putting the string in single or double quotes can work but then the value remains in quotes in the spreadsheet.
The best way to do this seems to be to use double quotes around the string AND prefix that with an equals sign - like this:
="229E10"
For reasons that I do not understand, Excel will strip the extra formatting off the string and treat the contents as plain text. This also works for arbitrary strings, such as ="ABC"
Tuesday, August 14, 2012
Installing OpenCV Ruby gem on mac OS X
In my previous post I showed how to Install the OpenCV computer vision library on Mac OS X Lion.
I want to use the Ruby interface to the library and of the various project forks I went with https://github.com/ruby-opencv/ruby-opencv
The github page has several alternate ways to install the interface, but installing it as a gem is the most mainstream. Even so, you need to do a bit more work than usual. First create an install directory for the 'raw' gem and clone it from github:
Get yourself an image file with a few faces (looking directly at the camera) to test it on.

Pretty amazing, if you ask me - Not perfect but three out of four ain't bad !
Now on to some real experiments with OpenCV - I can't wait...
I want to use the Ruby interface to the library and of the various project forks I went with https://github.com/ruby-opencv/ruby-opencv
The github page has several alternate ways to install the interface, but installing it as a gem is the most mainstream. Even so, you need to do a bit more work than usual. First create an install directory for the 'raw' gem and clone it from github:
$ mkdir opencv_install $ cd opencv_install/ $ git clone git://github.com/ruby-opencv/ruby-opencv.git $ cd ruby-opencv/ $ git checkout master $ bundle install $ rake gem $ gem install pkg/opencv-*.gem -- --with-opencv-dir=/usr/local/Cellar/opencv/2.4.2Your opencv directory may not be identical to mine but this is where homebrew should place it. For me, that was all I needed to do before copying the examples from the github page and trying things out ! Here is my version of the basic image display program:
#!/usr/bin/env ruby
require "opencv"
abort "Usage: #{$0} ![]() " unless ARGV.length == 1
image = OpenCV::IplImage.load(ARGV[0])
window = OpenCV::GUI::Window.new("preview")
window.show(image)
OpenCV::GUI::wait_key
" unless ARGV.length == 1
image = OpenCV::IplImage.load(ARGV[0])
window = OpenCV::GUI::Window.new("preview")
window.show(image)
OpenCV::GUI::wait_key
When you run the script with an image file, you can quit by typing 'q' in the resulting image window.
Now for the fun stuff. Here is my version of the github page face detection script. Face detection uses 'haarcascade' classifier files which live in your OpenCV library directory. With my Homebrew installation these are found in /usr/local/Cellar/opencv/2.4.2/share/OpenCV/haarcascadesGet yourself an image file with a few faces (looking directly at the camera) to test it on.
#!/usr/bin/env ruby
require "opencv"
abort "Usage: #{$0} source_image_file dest_image_file" unless ARGV.length == 2
classifiers_dir = "/usr/local/Cellar/opencv/2.4.2/share/OpenCV/haarcascades"
data = File.join(classifiers_dir, "haarcascade_frontalface_alt.xml")
detector = OpenCV::CvHaarClassifierCascade::load(data)
image = OpenCV::IplImage.load(ARGV[0])
detector.detect_objects(image).each do |region|
color = OpenCV::CvColor::Red
image.rectangle! region.top_left, region.bottom_right, :color => color
end
image.save_image(ARGV[1])
Make the file executable, run the script and then view the output file
$ chmod a+x findface.rb $ ./findface.rb smiths.jpg output.jpg $ open output.jpgAnd you should something along the lines of this:

Pretty amazing, if you ask me - Not perfect but three out of four ain't bad !
Now on to some real experiments with OpenCV - I can't wait...
Installing the OpenCV library on Mac OS X Lion using Homebrew
OpenCV (Open Source Computer Vision) is a remarkable library of functions for real time computer vision.
I'm interested in using it on to recognize buildings in satellite/aerial photographs - I'll explain more if I get the idea to work.
The first step is to get OpenCV up and running on my Mac (OS X Lion 10.7.4). The library has a lot of dependencies that need to be installed but thankfully there is a Homebrew recipe for doing all of the heavy lifting... almost... I ran into a few problems but here is what I needed to do.
In principle all you need is:
1: brew wanted me to update my version of Xcode from 4.2 to 4.3
On Lion you update Xcode via the App store and it turns out that 4.4 is available. So I installed that and reran 'brew install opencv'
2: brew then complained that the Python package 'numby' (Numerical Python) was not installed. Brew does not install Python dependencies but suggested that I do this with:
I've got two versions of python installed (via homebrew)
Given the problem with easy_install, I went with a manual installation
1: Download the tar file for the latest stable version of numby
http://sourceforge.net/projects/numpy/files/NumPy/1.6.2/
2: Unpack the file into a temporary directory and cd into it
3: Run the python setup script
All being well you can now run
I'm interested in using it on to recognize buildings in satellite/aerial photographs - I'll explain more if I get the idea to work.
The first step is to get OpenCV up and running on my Mac (OS X Lion 10.7.4). The library has a lot of dependencies that need to be installed but thankfully there is a Homebrew recipe for doing all of the heavy lifting... almost... I ran into a few problems but here is what I needed to do.
In principle all you need is:
$ brew update $ brew install opencvBut I got two errors:
1: brew wanted me to update my version of Xcode from 4.2 to 4.3
On Lion you update Xcode via the App store and it turns out that 4.4 is available. So I installed that and reran 'brew install opencv'
2: brew then complained that the Python package 'numby' (Numerical Python) was not installed. Brew does not install Python dependencies but suggested that I do this with:
$ easy_install numbyI did that but I still got the error.
I've got two versions of python installed (via homebrew)
$ python --version Python 2.7.3 $ python3 --version Python 3.2.3For our purposes you only want to deal with Python 2 - version 3 should work but the homebrew package seems to want version 2
Given the problem with easy_install, I went with a manual installation
1: Download the tar file for the latest stable version of numby
http://sourceforge.net/projects/numpy/files/NumPy/1.6.2/
2: Unpack the file into a temporary directory and cd into it
3: Run the python setup script
$ python setup.py installSit back and relax as this takes a while. Everything went smoothly for me and hopefully for you too.
All being well you can now run
$ brew install opencvAgain this takes a while - about 9 minutes on my box. You will get a message at the end of the output telling you to add the following to your .bash_profile
export PYTHONPATH="/usr/local/lib/python2.7/site-packages:$PYTHONPATH"OpenCV has an excellent interface to Python, but I work primarily in Ruby so the next step for me is to get an OpenCV ruby gem set up and start to do some image processing. The next post on this blog will cover that.
Thursday, August 9, 2012
Variable substitution in Ruby sub/gsub replacement strings
With the sub and gsub methods in Ruby you can extract components of the matching string and use them in the replacement string.
For example, with input string 'Hello World' this replacement:
For example, with input string 'Hello World' this replacement:
mystring.sub(/(Wo)rld/, '\1bble') -> Hello WobbleNote the single quotes - if you use double quotes this happens:
mystring.sub(/(Wo)rld/, "\1bble") -> Hello \u0001bbleYou can use double quotes if you double escape the 'sequence' \1
mystring.sub(/(Wo)rld/, "\\1bble") -> Hello WobbleThis is very important if you want to include a ruby variable in the replacement string
s = "Mr."
mystring.sub(/(Wo)rld/, "#{s} \\1bble") -> Hello Mr. Wobble
Just remember 'double quotes' means 'double escapes'....Wednesday, August 8, 2012
Simple Example of How to Show / Hide Divs using JQuery
Here is a simple example of how to use JQuery to show or hide divs by clicking a link within a HTML page. You could make this even more minimal but I think this version gives you the simplest explanation.
I use this to embed comments in pages that I want to show to a client. When they are visible, the client gets to see my rationale for designing the page a certain way. But by clicking a 'Hide Comments' link, the client can see the final page design.
Clicking on the 'Hide Comments' link makes a 'Show Comments' link appear, and vice versa.
You can see the test page in its entirety at this github gist: https://gist.github.com/fa1782bd47872f4c98d6
Within the body of the page, each comment is entered in a div (or paragraph) block with the class 'comment'
At the top of the page are two links with '#' as the target and with the div ids of 'show-comments' and 'hide-comments' respectively.
In the Head of the page you need to include the JQuery library and then you create your custom script. This has three components:
The first defines the action taken when the Hide Comments link is clicked. All divs with class 'comment' and the Hide Comments link are hidden and the Show Comments link is shown.
The second component implements the reverse action when the Show Comments link is clicked. Now, all divs with class 'comment' are displayed along with the Hide Comments link. The Show Comments link is hidden.
You could do this with a single show/hide comments link. You would update the Javascript to use the 'toggle()' function instead of show()/hide() and you would update the text of the link as appropriate.
I use this to embed comments in pages that I want to show to a client. When they are visible, the client gets to see my rationale for designing the page a certain way. But by clicking a 'Hide Comments' link, the client can see the final page design.
Clicking on the 'Hide Comments' link makes a 'Show Comments' link appear, and vice versa.
You can see the test page in its entirety at this github gist: https://gist.github.com/fa1782bd47872f4c98d6
Within the body of the page, each comment is entered in a div (or paragraph) block with the class 'comment'
At the top of the page are two links with '#' as the target and with the div ids of 'show-comments' and 'hide-comments' respectively.
In the Head of the page you need to include the JQuery library and then you create your custom script. This has three components:
The first defines the action taken when the Hide Comments link is clicked. All divs with class 'comment' and the Hide Comments link are hidden and the Show Comments link is shown.
jQuery('#hide-comments').click(
function() {
jQuery('.comment, #hide-comments').hide();
jQuery('#show-comments').show();
}
);
The second component implements the reverse action when the Show Comments link is clicked. Now, all divs with class 'comment' are displayed along with the Hide Comments link. The Show Comments link is hidden.
jQuery('#show-comments').click(
function() {
jQuery('.comment, #hide-comments').show();
jQuery('#show-comments').hide();
}
);
Finally the Show Comments link is hidden when the page is loaded.You could do this with a single show/hide comments link. You would update the Javascript to use the 'toggle()' function instead of show()/hide() and you would update the text of the link as appropriate.
Thursday, July 19, 2012
Setting up Apache Solr on Mac OS X
Apache Solr is an incredibly flexible and capable text search engine that you can hook into other applications.
For a beginner it can appear to be very daunting due to the number of configuration options and when you start to read the documentation this feeling tends not to improve. But if you are using Mac OS X (a recent version) and have the homebrew package manager installed then the process is not too bad, at least to get you up and running.
These steps will help you get Solr installed and then load in data extracted from HTML, PDF and Word files.
In my configuration I have Mac OS X Lion and current versions of Java and homebrew.
1: Install Solr with homebrew - (brew update is always a good idea before a complex install)
$ brew update
$ brew install solr
This installs the software in /usr/local/Cellar/solr/3.6.0 (or whatever your version is)
2: Go to the example directory and start up Solr
$ cd /usr/local/Cellar/solr/3.6.0/libexec/example
$ java -jar start.jar
This will start up the Solr server using Jetty as the servlet container, which is just fine for our testing. Do not worry about using Tomcat etc until you are comfortable with a working Solr set up.
It is usually not good form to work inside a distribution directory - but for initial testing you should do this.
You will see a load of verbose output from Java in your terminal window, aside from any real errors, just ignore this.
3: Verify that the server is running
Browse to http://localhost:8982/solr/admin
You should the Administration interface with a gray background. There is not a lot you can do as you have not yet indexed any data, but this shows that you are running.
4: Load some data into Solr
$ cd exampledocs
$ java -jar post.jar *.xml
Note that the Solr server MUST be running before you try and load the documents.
5: Run your first query from the admin page
Enter 'video' in the Query form and hit 'Search'. You should see the contents of an XML file returned to you with 3 documents.
This demonstrates that the server is working, that you can index XML documents and query them. Solr does not provide you with a nice search interface. The intent is that your Rails, etc application sends queries and then parses out the XML results for display back to the user.
6: Extract text from other document types
What I want to use Solr for is to search text extracted from web pages, Word documents, etc. But this where the Solr documents started to really let me down.
This parsing is done by calling Apache Tika which is a complex software package with the sole aim of text extraction. The interface between Solr and Tika used to be called SolrCell and is now called the ExtractingRequestHandler. Don't worry about any of that for now! The Solr distribution has everything you need already in place - you just need to know how to use it...
Do not set up a custom Solr home directory for now. That is what the documentation suggests, it makes perfect sense but nothing will work if you do.
Save a few HTML files that contain a good amount of text into a temporary directory somewhere.
To load the contents of a file into the server and have it parse the text you need to use 'curl' to POST the data to a specific URL on the server. In this example my file is called index.html and I have cd'ed to the directory containing the file
$ curl "http://localhost:8983/solr/update/extract?literal.id=doc1&commit=true&uprefix=attr_&fmap.content=attr_content" -F "myfile=@index.html"
There are several things to note with this URL...
The server URI is http://localhost:8983/solr/update/extract
The parameters are
literal.id=doc1
commit=true
uprefix=attr_
fmap.content=attr_content
Literal.id provides a unique identifier for this this document in the index (doc1 in this case)
uprefix=attr_ adds the prefix 'attr_' to the name of each tag in the source document
fmap.content=attr_content specifies that the main text content of the page should be given the tag attr_content
commit=true actually commits the parsed data to the index
And then note how the file to be parsed is specified... as a quoted string passed with the -F flag to curl. The quoted string consists of a name for the uploaded file (myfile) followed by the path to the file preceded by the Ampersand character (@).
You can ignore what these mean for now with the exception that each document you load must have a unique document ID.
7: Verify that the text has been indexed
Go to the Admin interface and click 'Full Interface'. Set the number of rows returned to large number (50) and then search with the query *:* - this will return all the records in the index.
You should get back an XML page with the example data plus the text derived from your HTML file at the bottom.
8: Try loading other data types
Tika knows how to parse Word, Excel, PDF and other files.
Be aware that there may not be much text in certain files. This is especially true of PDF files which although they appear to have text when displayed, may have that text stored as an image.
9: Explore the example directory
Everything I've shown here should 'just work' as long as you worked in the example directory. In there you will see a 'solr' subdirectory which contains conf and data directories. The data directory is where the index files reside. In the conf directory you will see a solrconfig.xml file. This is the main location for specifying the various components that your Solr installation uses. The default values happen to work fine until you create your own 'Solr Home' directory elsewhere.
The problem is that the solrconfig.xml file contains various relative paths (like ../../lib) which will not work if you create a solr directory in an arbitrary location. Knowing this you can update those paths pretty easily, but if you created a custom solr home then you are in for a lot of frustration trying to figure out why nothing works. I went through that process - you shouldn't have to...
That should be enough to getting you started with Solr. The next steps are to link it to your web application, to load in a lot more data and to move it to a production servlet container like Tomcat.
For a beginner it can appear to be very daunting due to the number of configuration options and when you start to read the documentation this feeling tends not to improve. But if you are using Mac OS X (a recent version) and have the homebrew package manager installed then the process is not too bad, at least to get you up and running.
These steps will help you get Solr installed and then load in data extracted from HTML, PDF and Word files.
In my configuration I have Mac OS X Lion and current versions of Java and homebrew.
1: Install Solr with homebrew - (brew update is always a good idea before a complex install)
$ brew update
$ brew install solr
This installs the software in /usr/local/Cellar/solr/3.6.0 (or whatever your version is)
2: Go to the example directory and start up Solr
$ cd /usr/local/Cellar/solr/3.6.0/libexec/example
$ java -jar start.jar
This will start up the Solr server using Jetty as the servlet container, which is just fine for our testing. Do not worry about using Tomcat etc until you are comfortable with a working Solr set up.
It is usually not good form to work inside a distribution directory - but for initial testing you should do this.
You will see a load of verbose output from Java in your terminal window, aside from any real errors, just ignore this.
3: Verify that the server is running
Browse to http://localhost:8982/solr/admin
You should the Administration interface with a gray background. There is not a lot you can do as you have not yet indexed any data, but this shows that you are running.
4: Load some data into Solr
$ cd exampledocs
$ java -jar post.jar *.xml
Note that the Solr server MUST be running before you try and load the documents.
5: Run your first query from the admin page
Enter 'video' in the Query form and hit 'Search'. You should see the contents of an XML file returned to you with 3 documents.
This demonstrates that the server is working, that you can index XML documents and query them. Solr does not provide you with a nice search interface. The intent is that your Rails, etc application sends queries and then parses out the XML results for display back to the user.
6: Extract text from other document types
What I want to use Solr for is to search text extracted from web pages, Word documents, etc. But this where the Solr documents started to really let me down.
This parsing is done by calling Apache Tika which is a complex software package with the sole aim of text extraction. The interface between Solr and Tika used to be called SolrCell and is now called the ExtractingRequestHandler. Don't worry about any of that for now! The Solr distribution has everything you need already in place - you just need to know how to use it...
Do not set up a custom Solr home directory for now. That is what the documentation suggests, it makes perfect sense but nothing will work if you do.
Save a few HTML files that contain a good amount of text into a temporary directory somewhere.
To load the contents of a file into the server and have it parse the text you need to use 'curl' to POST the data to a specific URL on the server. In this example my file is called index.html and I have cd'ed to the directory containing the file
$ curl "http://localhost:8983/solr/update/extract?literal.id=doc1&commit=true&uprefix=attr_&fmap.content=attr_content" -F "myfile=@index.html"
There are several things to note with this URL...
The server URI is http://localhost:8983/solr/update/extract
The parameters are
literal.id=doc1
commit=true
uprefix=attr_
fmap.content=attr_content
Literal.id provides a unique identifier for this this document in the index (doc1 in this case)
uprefix=attr_ adds the prefix 'attr_' to the name of each tag in the source document
fmap.content=attr_content specifies that the main text content of the page should be given the tag attr_content
commit=true actually commits the parsed data to the index
And then note how the file to be parsed is specified... as a quoted string passed with the -F flag to curl. The quoted string consists of a name for the uploaded file (myfile) followed by the path to the file preceded by the Ampersand character (@).
You can ignore what these mean for now with the exception that each document you load must have a unique document ID.
7: Verify that the text has been indexed
Go to the Admin interface and click 'Full Interface'. Set the number of rows returned to large number (50) and then search with the query *:* - this will return all the records in the index.
You should get back an XML page with the example data plus the text derived from your HTML file at the bottom.
8: Try loading other data types
Tika knows how to parse Word, Excel, PDF and other files.
Be aware that there may not be much text in certain files. This is especially true of PDF files which although they appear to have text when displayed, may have that text stored as an image.
9: Explore the example directory
Everything I've shown here should 'just work' as long as you worked in the example directory. In there you will see a 'solr' subdirectory which contains conf and data directories. The data directory is where the index files reside. In the conf directory you will see a solrconfig.xml file. This is the main location for specifying the various components that your Solr installation uses. The default values happen to work fine until you create your own 'Solr Home' directory elsewhere.
The problem is that the solrconfig.xml file contains various relative paths (like ../../lib) which will not work if you create a solr directory in an arbitrary location. Knowing this you can update those paths pretty easily, but if you created a custom solr home then you are in for a lot of frustration trying to figure out why nothing works. I went through that process - you shouldn't have to...
That should be enough to getting you started with Solr. The next steps are to link it to your web application, to load in a lot more data and to move it to a production servlet container like Tomcat.
Wednesday, July 18, 2012
Installing Apache tomcat on Mac OS X Lion using homebrew
It is hard to overestimate how much I am grateful for the homebrew Mac OS X package manager.
Today I needed to setup Apache Tomcat on a OS X Lion machine. I already have homebrew installed and have used it to install a bunch of stuff.
All that is needed is:
$ brew install tomcat
I'll admit that this failed the first time that I tried it but running 'brew update' and then 'brew install tomcat' sorted that out - I guess if you've not used it for a while you should run 'brew update' as it is still evolving quite rapildly.
That installs the code into /usr/local/Cellar/tomcat/7.0.28
To start/stop the server from the command line you use the catalina shell script
$ /usr/local/Cellar/tomcat/7.0.28/bin/catalina run
[...]
$ /usr/local/Cellar/tomcat/7.0.28/bin/catalina stop
When it is running you can go to http://localhost:8080 and see a default tomcat information page with lots more info.
For me that default port is a problem as it is also the default for my nginx installation. But changing it is easy enough. Edit /usr/local/Cellar/tomcat/7.0.28/libexec/conf/server.xml and replace the instances of 808 with your preferred port. Rerun catalina and then go to your preferred URL.
For my purposes I want to start and stop the server manually but check the documents for how to link it to an instance of Apache.
Today I needed to setup Apache Tomcat on a OS X Lion machine. I already have homebrew installed and have used it to install a bunch of stuff.
All that is needed is:
$ brew install tomcat
I'll admit that this failed the first time that I tried it but running 'brew update' and then 'brew install tomcat' sorted that out - I guess if you've not used it for a while you should run 'brew update' as it is still evolving quite rapildly.
That installs the code into /usr/local/Cellar/tomcat/7.0.28
To start/stop the server from the command line you use the catalina shell script
$ /usr/local/Cellar/tomcat/7.0.28/bin/catalina run
[...]
$ /usr/local/Cellar/tomcat/7.0.28/bin/catalina stop
When it is running you can go to http://localhost:8080 and see a default tomcat information page with lots more info.
For me that default port is a problem as it is also the default for my nginx installation. But changing it is easy enough. Edit /usr/local/Cellar/tomcat/7.0.28/libexec/conf/server.xml and replace the instances of 808 with your preferred port. Rerun catalina and then go to your preferred URL.
For my purposes I want to start and stop the server manually but check the documents for how to link it to an instance of Apache.
Friday, July 6, 2012
Downloading CSV files in Rails
Providing a way to download data as a CSV file is a common feature in Rails applications.
There is a nice Railscasts episode on the topic here: Exporting CSV and Excel
I prefer to use a view template to generate my CSV as it gives me a lot of control on the fields that go into the file. But the standard way of invoking this from the controller does not provide a way to specify the filename for the downloaded file
respond_to do |format|
format.html
format.csv
end
With a Show action, for example '/posts/25.csv', the downloaded file would be called '25.csv' which is not useful.
In a response to this Stackoverflow question, Clinton R. Nixon offers up a nice solution.
He has a method called render_csv in his application controller that takes an optional filename. Before calling regular render on your template, it sets several HTTP headers - most importantly a Content-Disposition header with the desired filename. It adds the '.csv' suffix for you and uses the action name as the default if no name if supplied.
With this in place you modify your controller like this
respond_to do |format|
format.html
format.csv { render_csv('myfile') }
end
Very nice and very useful...
There is a nice Railscasts episode on the topic here: Exporting CSV and Excel
I prefer to use a view template to generate my CSV as it gives me a lot of control on the fields that go into the file. But the standard way of invoking this from the controller does not provide a way to specify the filename for the downloaded file
respond_to do |format|
format.html
format.csv
end
With a Show action, for example '/posts/25.csv', the downloaded file would be called '25.csv' which is not useful.
In a response to this Stackoverflow question, Clinton R. Nixon offers up a nice solution.
He has a method called render_csv in his application controller that takes an optional filename. Before calling regular render on your template, it sets several HTTP headers - most importantly a Content-Disposition header with the desired filename. It adds the '.csv' suffix for you and uses the action name as the default if no name if supplied.
With this in place you modify your controller like this
respond_to do |format|
format.html
format.csv { render_csv('myfile') }
end
Very nice and very useful...
Using Sass in Rails 3.0
Sass is the default CSS preprocessor in Rails3.1 and it is tied into the asset pipeline machinery that first appears in 3.1.
I am migrating a complex app from 3.0 to 3.1 and I want to use Sass in the 3.0 production version before I make the big jump to 3.1. So far I have been using Less and the more plugin.
I recently wrote up my experience moving from Less to Sass syntax but here I want to cover the Rails side of things.
Here are the steps involved in my Less to Sass transition in Rails 3.0.5
Part 1: Remove all traces of Less
1: Remove the less gem from your Gemfile
2: Rename the app/stylesheets folder to something else
3: Move or delete the Less plugin in vendor/plugins/more so that the app doesn't see it on start up
Part 2: Set up Sass
4: Add the sass gem to your Gemfile ( gem 'sass' )
5: Run 'bundle install'
6: Create a sass directory under public/stylesheets
7: Leave any straight css file in public/stylesheets
8: Place any SCSS files in the sass directory - these could be new files or converted Less files - give them the .scss suffix
9: Remove or rename any matching css files in the parent directory
10: Restart your server and browse to your site
All being well Sass has worked in the background, created new versions of the CSS files and put them in public/stylesheets. Look for those files and test out the operation by, say, changing a background color in the SCSS file, saving the file and reloading the page. You should see the change implemented.
There are various options that you can set in your environment.rb file or similar. But you don't need any of these. Likewise you don't need to run any rake tasks or explicitly setup sass to watch certain files. It just works.
With this set up you can now get comfortable with Sass such that moving to 3.1 and the Asset Pipeline should be straightforward.
I am migrating a complex app from 3.0 to 3.1 and I want to use Sass in the 3.0 production version before I make the big jump to 3.1. So far I have been using Less and the more plugin.
I recently wrote up my experience moving from Less to Sass syntax but here I want to cover the Rails side of things.
Here are the steps involved in my Less to Sass transition in Rails 3.0.5
Part 1: Remove all traces of Less
1: Remove the less gem from your Gemfile
2: Rename the app/stylesheets folder to something else
3: Move or delete the Less plugin in vendor/plugins/more so that the app doesn't see it on start up
Part 2: Set up Sass
4: Add the sass gem to your Gemfile ( gem 'sass' )
5: Run 'bundle install'
6: Create a sass directory under public/stylesheets
7: Leave any straight css file in public/stylesheets
8: Place any SCSS files in the sass directory - these could be new files or converted Less files - give them the .scss suffix
9: Remove or rename any matching css files in the parent directory
10: Restart your server and browse to your site
All being well Sass has worked in the background, created new versions of the CSS files and put them in public/stylesheets. Look for those files and test out the operation by, say, changing a background color in the SCSS file, saving the file and reloading the page. You should see the change implemented.
There are various options that you can set in your environment.rb file or similar. But you don't need any of these. Likewise you don't need to run any rake tasks or explicitly setup sass to watch certain files. It just works.
With this set up you can now get comfortable with Sass such that moving to 3.1 and the Asset Pipeline should be straightforward.
Thursday, July 5, 2012
Histograms in Mac OS X Numbers
I am always creating histograms based on CSV files where the first column is the category and the second is the value - like this:
I want to load this into Excel or Numbers and create a bar chart where each bar is labeled with the year on the X axis and the height of the bar is the value for that category.
Load in the CSV file and you will have two columns of data.
The trick with Numbers is to specify the first column (year) as a Header column.
Go to the first column header (A) and use the pull down menu to select 'Convert to Header Column'. That makes the background for these cells gray and makes the text bold.
Now go to the first row header (1) and use that pull down to select 'Convert to Header Row'.

Select the entire table by clicking the corner cell at the top left, then go to 'Charts' icon in the toolbar and select your preferred type of bar chart. You will see the chart appear with the Years as the X axis and the column header(s) as the data series labels.
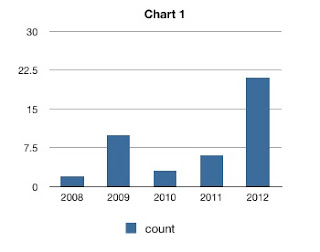
If you type data directly into a new Numbers sheet then the headers will be set up automatically, but that does not happen when you import a CSV file.
year,count 2008,2 2009,10 2010,3 2011,6 2012,21
I want to load this into Excel or Numbers and create a bar chart where each bar is labeled with the year on the X axis and the height of the bar is the value for that category.
Load in the CSV file and you will have two columns of data.
The trick with Numbers is to specify the first column (year) as a Header column.
Go to the first column header (A) and use the pull down menu to select 'Convert to Header Column'. That makes the background for these cells gray and makes the text bold.
Now go to the first row header (1) and use that pull down to select 'Convert to Header Row'.
Select the entire table by clicking the corner cell at the top left, then go to 'Charts' icon in the toolbar and select your preferred type of bar chart. You will see the chart appear with the Years as the X axis and the column header(s) as the data series labels.

If you type data directly into a new Numbers sheet then the headers will be set up automatically, but that does not happen when you import a CSV file.
Wednesday, July 4, 2012
Rails 3 YAML parse error and RedCloth
I moved a Rails 3.0.5 application to a new server with ruby 1.9.2, under rbenv. It had been working fine before but now I got this:
$ rails server
/Users/jones/.rbenv/versions/1.9.2-p290/lib/ruby/1.9.1/psych.rb:148:in `parse': couldn't parse YAML at line 183 column 9 (Psych::SyntaxError)
from /Users/jones/.rbenv/versions/1.9.2-p290/lib/ruby/1.9.1/psych.rb:148:in `parse_stream'
from /Users/jones/.rbenv/versions/1.9.2-p290/lib/ruby/1.9.1/psych.rb:119:in `parse'
from /Users/jones/.rbenv/versions/1.9.2-p290/lib/ruby/1.9.1/psych.rb:106:in `load'
from /Users/jones/.rbenv/versions/1.9.2-p290/lib/ruby/gems/1.9.1/gems/RedCloth-4.2.2/lib/redcloth/formatters/latex.rb:6:in `<module:LATEX>'
from /Users/jones/.rbenv/versions/1.9.2-p290/lib/ruby/gems/1.9.1/gems/RedCloth-4.2.2/lib/redcloth/formatters/latex.rb:3:in `<top (required)>'
[...]
There are a lot of posts about this error on the web. Some recommend specifying the 'syck' Yaml engine in the boot.rb file or messing with your libyaml setup. This did not work for me.
The solution turned out to be simple. You can see from the error message that the error is coming from the RedCloth gem. Previously I had been using version 4.2.2 (look in Gemfile.lock) even though I had not explicitly set that version.
On the new system I had version 4.2.9 installed. When I set this explicitly in the Gemfile I could start up the server just fine, after running 'bundle install'.
gem 'RedCloth', '>= 4.2.9'
Thursday, June 14, 2012
logit - selective logging of commands from a Bash shell
I spend a lot of time running custom scripts on datasets in a unix bash shell - typically I'm running various tools on DNA and protein sequence datasets. I need to try different tools, edit files and change parameters.
I wanted a way to capture those commands that worked and ignore all the others that simply listed directories, ran the editor, etc. Cutting and pasting from the shell history was really inefficient and the output of script was too voluminous.
To solve this I have written logit - a tool that lets you selective log commands and comments to a file while you work in a shell.
logit consists of a Ruby script and an associated bash shell script. When you run 'logit start' it creates a custom bash sub shell that you do your work in.
You can log comments to the log file with:
$ logit 'here is a comment'
And you log the last command you ran with just:
$ logit
There are other options to help you log commands further back in your history.
The resulting log file contains only those commands and comments that you chose to log. As such it serves as a concise record of a work session and may form the basis for an executable script in itself.
The regular Bash history mechanism is does not allow you to record lines from your history in a files. I'm not clear why but the cleanest solution I could come up with was the pairing of a Ruby and a Bash script. In practice you only ever deal with the Ruby script.
The code is distributed freely under the MIT license and can be found on Github at https://github.com/craic/logit
I wanted a way to capture those commands that worked and ignore all the others that simply listed directories, ran the editor, etc. Cutting and pasting from the shell history was really inefficient and the output of script was too voluminous.
To solve this I have written logit - a tool that lets you selective log commands and comments to a file while you work in a shell.
logit consists of a Ruby script and an associated bash shell script. When you run 'logit start' it creates a custom bash sub shell that you do your work in.
You can log comments to the log file with:
$ logit 'here is a comment'
And you log the last command you ran with just:
$ logit
There are other options to help you log commands further back in your history.
The resulting log file contains only those commands and comments that you chose to log. As such it serves as a concise record of a work session and may form the basis for an executable script in itself.
The regular Bash history mechanism is does not allow you to record lines from your history in a files. I'm not clear why but the cleanest solution I could come up with was the pairing of a Ruby and a Bash script. In practice you only ever deal with the Ruby script.
The code is distributed freely under the MIT license and can be found on Github at https://github.com/craic/logit
Tuesday, June 12, 2012
CSS and Rails - Migrating from Less to Sass
In my Rails projects over the past couple of years I have been using Less to make my CSS files easier to work with. Less is a CSS pre-processor that lets you use variables for color, etc.
Less is pretty similar to Sass and I didn't see any real reason to move away from it. But then Rails 3.1 made the decision to uses Sass and CoffeeScript as CSS and JavaScript preprocessors. So now I want to migrate my Less files over to Scss (the v2 format of Sass) so I can go with the flow in current Rails versions.
Sass comes with a conversion tool called sass-convert that you can find in the bin directory of the gem.
You can find where that is located with 'gem which sass'. But this gave me this error:
NameError: undefined method `build' for module `Less::StyleSheet::Mixin4'
From the sass github site it seems like sass -convert has not kept up with changes in Less and there seems little motivation to fix the problem.
Never mind - the Less and Scss syntaxes are pretty similar and my files do not include anything too complex, so manually converting them in an editor is quite feasible. In fact the main difference is that Less prefixes variables with @ and Sass uses $. The important exception here is that @import should not be changed as it is exactly the same in Sass.
Less has an equivalent to Sass Mixins. You create a custom class and then insert that into other CSS blocks. Here is an example followed by the Sass equivalent.
.my-mixin {
color: red;
}
.my-class {
width: 200px;
.my-mixin;
}
In Sass you would write:
@mixin my-mixin {
color: red;
}
.my-class {
width: 200px;
@include my-mixin;
}
Making this conversion is easy enough to do with find and replace in your editor.
The easiest way to validate the modified files is to run sass on them and check the css.
$ sass my.scss my.css
You can try validating the CSS using a service like http://jigsaw.w3.org/css-validator/validator
Less is pretty similar to Sass and I didn't see any real reason to move away from it. But then Rails 3.1 made the decision to uses Sass and CoffeeScript as CSS and JavaScript preprocessors. So now I want to migrate my Less files over to Scss (the v2 format of Sass) so I can go with the flow in current Rails versions.
Sass comes with a conversion tool called sass-convert that you can find in the bin directory of the gem.
You can find where that is located with 'gem which sass'. But this gave me this error:
NameError: undefined method `build' for module `Less::StyleSheet::Mixin4'
From the sass github site it seems like sass -convert has not kept up with changes in Less and there seems little motivation to fix the problem.
Never mind - the Less and Scss syntaxes are pretty similar and my files do not include anything too complex, so manually converting them in an editor is quite feasible. In fact the main difference is that Less prefixes variables with @ and Sass uses $. The important exception here is that @import should not be changed as it is exactly the same in Sass.
Less has an equivalent to Sass Mixins. You create a custom class and then insert that into other CSS blocks. Here is an example followed by the Sass equivalent.
.my-mixin {
color: red;
}
.my-class {
width: 200px;
.my-mixin;
}
In Sass you would write:
@mixin my-mixin {
color: red;
}
.my-class {
width: 200px;
@include my-mixin;
}
Making this conversion is easy enough to do with find and replace in your editor.
The easiest way to validate the modified files is to run sass on them and check the css.
$ sass my.scss my.css
You can try validating the CSS using a service like http://jigsaw.w3.org/css-validator/validator
Thursday, June 7, 2012
Setting a Title for a Tab in iTerm2 on Mac OS X
iTerm2 (http://www.iterm2.com) by George Nachman is an excellent terminal emulator for Mac OS X that is highly configurable. I it prefer over the system Terminal application.
I tend to have a number of terminal sessions open at the same time and for a while I have wanted a way to give each Tab in the window an informative name. You can do that through the iTerm2 preferences but I wanted a way to set it directly from the shell command line.
iTerm2 can be scripted via AppleScript and so I wrote a simple script to do the job. It uses a system application called osascript which will execute a AppleScript script from the Unix command line.
The code is freely available at https://github.com/craic/iterm_title - see the README for more details.
The code should be a useful starting point if you want to write something in AppleScript that you can call from UNIX.
I tend to have a number of terminal sessions open at the same time and for a while I have wanted a way to give each Tab in the window an informative name. You can do that through the iTerm2 preferences but I wanted a way to set it directly from the shell command line.
iTerm2 can be scripted via AppleScript and so I wrote a simple script to do the job. It uses a system application called osascript which will execute a AppleScript script from the Unix command line.
The code is freely available at https://github.com/craic/iterm_title - see the README for more details.
The code should be a useful starting point if you want to write something in AppleScript that you can call from UNIX.
Wednesday, May 30, 2012
rbenv - quick start
rbenv is a way to handle multiple versions of Ruby on a single machine and is an alternative to rvm.
I have been using rvm for some time and it works fine, but rbenv seems to have a slight edge in terms of simplicity and, perhaps, transparency in the way it handles version specific gems.
I installed it on a new machine with Mac OS X Lion using homebrew
Not surprisingly, Jruby required that Java be installed but it was smart enough to trigger the download automatically.
You need to add two lines to your .bashrc, .bash_profile or whatever config file is appropriate for your preferred shell. Then create a new shell to pick up the definitions.
The documentation is pretty straightforward in terms of setting different versions of Ruby in different projects.
Things get a bit confusing when it comes time to set up gems. rvm places copies of each gem in directories that are linked to each ruby version. By and large, rbenv doesn't mess with them.
With rbenv you install specific gems into a single system wide directory, as you would with a single Ruby version. For a given project you specify the required gems in a Gemfile in the project directory and you run
to make sure that you have correct versions of all the gems for that given project.
If you have installed a specific gem but find that it does not work or does not appear to exist then run this to, hopefully, fix the issue.
I have been using rvm for some time and it works fine, but rbenv seems to have a slight edge in terms of simplicity and, perhaps, transparency in the way it handles version specific gems.
I installed it on a new machine with Mac OS X Lion using homebrew
$ brew update
$ brew install rbenv
$ brew install ruby-build
You can see which versions of ruby are available using
$ rbenv versions
You can install them like this
$ rbenv install 1.9.3-p0
$ rbenv install 1.8.7-p302
$ rbenv install jruby-1.6.7You need to add two lines to your .bashrc, .bash_profile or whatever config file is appropriate for your preferred shell. Then create a new shell to pick up the definitions.
export PATH="$HOME/.rbenv/bin:$PATH"
eval "$(rbenv init -)"
Things get a bit confusing when it comes time to set up gems. rvm places copies of each gem in directories that are linked to each ruby version. By and large, rbenv doesn't mess with them.
With rbenv you install specific gems into a single system wide directory, as you would with a single Ruby version. For a given project you specify the required gems in a Gemfile in the project directory and you run
$ bundle execto make sure that you have correct versions of all the gems for that given project.
If you have installed a specific gem but find that it does not work or does not appear to exist then run this to, hopefully, fix the issue.
$ rbenv rehashTuesday, February 21, 2012
Running Ruby executable in a world-writable directory
Just now I needed to run a Ruby executable that was located in a world-writable directory.
Normally this is something that you never want to do - anyone could put an executable into your directory and/or replace your script with their own. BUT sometimes you just need to do this - in my case I am in a secure environment, working with collaborators but we have not been able to get IT to set us up as a 'group' as yet.
The problem is that Ruby will issue a warning about "Insecure world writable directory" every time you run your script.
The real solution is to get past the need for those permissions. But in the short term I just want to get rid of the warnings.
There are two options:
You can pass the -W0 (that's a zero) flag to ruby
$ ruby -W0
But I use this 'hash bang' line at the start of all my scripts:
#!/usr/bin/env ruby
and I can't figure out how to pass the flag correctly in this case
The alternative is to add this line right after the hash bang line
$VERBOSE = nil
That does work. It clearly silences any other warnings that I might want to see but at least it gets me past my current issue.
Normally this is something that you never want to do - anyone could put an executable into your directory and/or replace your script with their own. BUT sometimes you just need to do this - in my case I am in a secure environment, working with collaborators but we have not been able to get IT to set us up as a 'group' as yet.
The problem is that Ruby will issue a warning about "Insecure world writable directory" every time you run your script.
The real solution is to get past the need for those permissions. But in the short term I just want to get rid of the warnings.
There are two options:
You can pass the -W0 (that's a zero) flag to ruby
$ ruby -W0
But I use this 'hash bang' line at the start of all my scripts:
#!/usr/bin/env ruby
and I can't figure out how to pass the flag correctly in this case
The alternative is to add this line right after the hash bang line
$VERBOSE = nil
That does work. It clearly silences any other warnings that I might want to see but at least it gets me past my current issue.
Wednesday, February 15, 2012
Compiling Ruby 1.9.3 from source
I had to install Ruby 1.9.3 from source today.
Ruby comes with a load of documentation but I never use it. It's just easier to look it up on the web. But creating and installing that documentation takes a huge amount of time.
To disable it pass this option to 'configure'
$ ./configure --disable-install-doc
The other issue I had to deal with was that libyaml was installed in a non-standard location. With some libraries you can pass a specific option to 'configure' but not here... Instead you have to add the include and lib directories to Environment variables, like this:
$ export CPPFLAGS="-I/my/location/include"
$ export LDFLAGS="-L/my/location/lib"
'configure' will pick those up without any additional arguments.
Ruby comes with a load of documentation but I never use it. It's just easier to look it up on the web. But creating and installing that documentation takes a huge amount of time.
To disable it pass this option to 'configure'
$ ./configure --disable-install-doc
The other issue I had to deal with was that libyaml was installed in a non-standard location. With some libraries you can pass a specific option to 'configure' but not here... Instead you have to add the include and lib directories to Environment variables, like this:
$ export CPPFLAGS="-I/my/location/include"
$ export LDFLAGS="-L/my/location/lib"
'configure' will pick those up without any additional arguments.
Friday, January 27, 2012
Getting absolute paths with the Unix ls command
The standard Unix command ls lists filenames and directories in the specified directory. The default behaviour is to list just the filenames as including the full pathname would clutter the screen.
But sometimes you want the absolute paths. I need this all the time if I want to create a file containing a list fo filenames. The obvious command to get all the YAML files, for example, is:
$ ls -1 *yml
A.yml
B.yml
In order to get the full pathnames you need to use this:
$ ls -1 -d $PWD/*yml
/home/jones/A.yml
/home/jones/B.yml
But sometimes you want the absolute paths. I need this all the time if I want to create a file containing a list fo filenames. The obvious command to get all the YAML files, for example, is:
$ ls -1 *yml
A.yml
B.yml
In order to get the full pathnames you need to use this:
$ ls -1 -d $PWD/*yml
/home/jones/A.yml
/home/jones/B.yml
Wednesday, January 25, 2012
Wolfram CDF Player and Chrome Browser
Wolfram Computable Document Format (CDF) is a way to embed interactive documents into web pages, in particular those that perform calculations in response to a user changing the parameters. For example you can create graphs of functions that will change as the function is modified. It is an extension of the Wolfram Mathematica software.
It looks really promising for some applications and you should check out their demonstrations - some impressive, some not so much.
You 'play' CDF files using a browser plugin - just like Flash - and these are available for all the current browsers.
I'm running it on Google Chrome on Mac OS X on a fairly recent laptop. It performs OK depending on the specific application and the amount of data it is asked to push around. But when you close that window or move to another page the CDF player process continues to run. In my case that was taking 5% of my cpu and 66MB of memory and it continued to do so for perhaps 10 minutes after the page was closed.
This sort of drain on your cpu, due to the plugin, is fairly common - just look at everything going on in Activity Monitor when you are browsing an 'active' web page with ads, etc.
In Chrome you can go to Window -> Task Manager, select a process and End it - but that didn't appear to do anything in my case.
CDF looks very interesting but if it requires too many resources, and then fails to release them properly, then it is not likely to be broadly adopted. It is something to keep an eye on, for sure.
It looks really promising for some applications and you should check out their demonstrations - some impressive, some not so much.
You 'play' CDF files using a browser plugin - just like Flash - and these are available for all the current browsers.
I'm running it on Google Chrome on Mac OS X on a fairly recent laptop. It performs OK depending on the specific application and the amount of data it is asked to push around. But when you close that window or move to another page the CDF player process continues to run. In my case that was taking 5% of my cpu and 66MB of memory and it continued to do so for perhaps 10 minutes after the page was closed.
This sort of drain on your cpu, due to the plugin, is fairly common - just look at everything going on in Activity Monitor when you are browsing an 'active' web page with ads, etc.
In Chrome you can go to Window -> Task Manager, select a process and End it - but that didn't appear to do anything in my case.
CDF looks very interesting but if it requires too many resources, and then fails to release them properly, then it is not likely to be broadly adopted. It is something to keep an eye on, for sure.
Wednesday, January 4, 2012
Disabling Spotlight (mds) on Mac OS X (Snow Leopard)
I run a lot of command line scripts on my laptop - some of which can run for hours. I want to continue using the machine for reading mail, etc., but I don't want any other intensive task sucking up the cpu cycles. So I shut down iTunes, don't watch any videos, etc.
But sometimes I see some other process taking all my cycles. The odds are that it is either something to do with Flash or it is a process called mds.
mds is the indexing software that powers Spotlight - the built in Mac search facility.
I suspect that when I'm generating gigabytes of data and hundreds of files in one of my compute jobs, mds is responding by trying to index them at the same time.
I don't use spotlight at all, so let's turn it off and see if that helps.
This turns it off:
$ sudo mdutil -a -i off
This turns it back on:
$ sudo mdutil -a -i on
Turning it back on will presumably trigger a big mds run as it plays catch up, so run this command only when you can afford the cycles.
But sometimes I see some other process taking all my cycles. The odds are that it is either something to do with Flash or it is a process called mds.
mds is the indexing software that powers Spotlight - the built in Mac search facility.
I suspect that when I'm generating gigabytes of data and hundreds of files in one of my compute jobs, mds is responding by trying to index them at the same time.
I don't use spotlight at all, so let's turn it off and see if that helps.
This turns it off:
$ sudo mdutil -a -i off
This turns it back on:
$ sudo mdutil -a -i on
Turning it back on will presumably trigger a big mds run as it plays catch up, so run this command only when you can afford the cycles.
Subscribe to:
Posts (Atom)

